
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- #스윙 #함수 #Swing
- #웹 #HTTP 프로토콜
- #프로그래밍 기초
- #웹 #정의 #5대 브라우저 #
- #자바
- #Web #웹 #jsp #servlet
- #자바 #입출력 #함수
- #BigDecimal
- #자바 #스윙관련 함수 #API보고 정리했음
- #오라클 #11g #테이블
- #제약 조건 #함수 #컬럼 변경 #테이블 변경& 삭제
- #돔 트리 #form 태그 #이스케이프문자 #시작태그 #form태그
- #웹 #중요한 것
- #함수 #VIEW #시퀀스 #INDEX
- #자바 #파일 #함수
- #Ajax #EL #JSTL
- #StringBuffer #자바 #
- #오라클 #함수 #MAX() #MIN() #LPAD() #SUBSTR() #TO_CHAR() #복사 #지우기 #수정
- #자바 #오라클 #JDBC
- #리뷰 #CSS #선택자
- #48일차 #한 내용 #요약
- #jdbc #자바
- #오라클 #계정 생성 #테이블 #생성 #조회 #추가
- #오라클 #용어 정리 #데이터 타입 #비교 연산자 #논리 연산자 #SELECT 문
- #자바 #오라클 #연동
- #자바 #입출력
- #HTML4.01또는 5의 차이 #parsing #웹브라우저 #form 태그 #태그 속성 #id #name
- #스프링 프레임 워크 #인코딩 #컨텍스트 #환경설정
- #함수 #키워드 #조인 #서브쿼리
- #오라클 #자바 #연동
- Today
- Total
IT journey
Python-모듈 random, 데이터 수를 세는 함수 본문
직접 내용 정리하고 만든 예이니 퍼가실 때는 출처를 남겨주세요 :)
※ 도움이 될 만한 포스팅
참고로, 최근 포스팅 순서대로 정리해두었습니다.
Python - 내장함수 2편과 이터레이터,제너레이터,코루틴,정규표현식
Python - 모듈(외장함수) 2편(feat.파일 입출력과 추상클래스...)
random 모듈
Python - 모듈(외장함수) 1편 에 나온 random 모듈에 대해 더 자세히 알아보겠습니다.
참고하고 싶으신 분들은 아래 글을 참고해주시길 부탁드립니다.
Python - 모듈(외장함수) 1편
직접 내용 정리하고 만든 예이니 퍼가실 때는 출처를 남겨주세요:) 모듈(외장함수) 정의 함수나 변수 또는 클래스들을 모아 놓은 파일을 말합니다. 쉽게 말해, 다른 파이썬 프로그램에서 불러서
step-journey.tistory.com
(1) 난수
(정의)
0.0~1.0 사이의 실수 값을 말합니다.
import numpy as np
#0~1사이의 난수가 나옵니다.
np.random.rand()
#seed를 설정해서 난수를 발생하게 되면 완전히 다른 난수값을 발생시킬 수 있습니다.
np.random.seed(0)
np.random.rand(5)(난수를 생성하는 명령)
○ rand는 0~1 사이의 균일분포입니다.
여기서, 균일분포란 아래 그림과 같습니다.
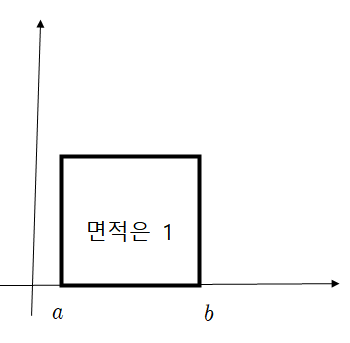
○ randn은 가우시안 표준 정규 분포입니다. 이 분포의 기대값(평균값)은 0, 표준편차는 1입니다.
○ randint은 균일 분포의 정수 난수입니다.
randint의 인수는 low,high,size로
여기서 high값이 없으면 low와 0 사이의 숫자로 인식하고,
있으면 low~high 사이 숫자로 인식합니다.
이때의 size는 난수의 개수를 의미합니다.
import numpy as np
np.random.rand(5)
np.random.randn(5,5)
np.random.randn(10)
#randint의 예
#high가 없는 경우
np.random.randint(5,size=5)
#high가 10인 경우
np.random.randint(5,10,size=5)
#high가 10이고 2행 5열일 경우
np.random.randint(5,10,size=(2,5))
(2) shuffle
import numpy as np
x = np.arange(5)
np.random.shuffle(x) #데이터의 순서를 바꾸는 함수입니다.(shuffle)
x(3) choice
○ [데이터 샘플링]
이미 있는 데이터 집합에서 무작위로 선택하는 것을 샘플링(sampling)이라고 합니다.
○ np.random.choice(a,size,replce=True/False,p)
a는 원본데이터, 정수이면 range(a)를 씁니다.
size는 샘플 숫자를 말합니다.
replace=True이면 한번 선택한 데이터를 다시 뽑을 수 있습니다.
p는 배열로, 각 데이터가 선택될 수 있는 확률입니다.
○ 위에서 나온 shuffle 코드처럼 하고싶을 경우에는 아래와 같이 합니다.
import numpy as np
x=np.random.choice(5,5,replace=False)
x○ choice 예
import numpy as np
x1=np.random.choice(5,5,replace=True)
x1
x2=np.random.choice(5,15,p=[0,0.3,0.4,0.3,0])
x2데이터 수를 세는 함수
1. unique
데이터에서 중복된 값을 제거하고 중복되지 않는 값의 리스트를 출력합니다.
import numpy as np
a=np.unique([27,27,1,1,5,5])
a1=([27,27,1,1,5,5])
#return_counts= True 설정이면 데이터의 개수도 출력
au,count=np.unique(a1,return_counts=True)
2. bincount
import numpy as np
#minlength는 0~4까지
count=np.bincount([0,0,1,1,4,3],minlength=5)
#0이 2개, 1이 2개, 2가 0개, 3이 1개, 4가 1개
count '개인공부공간 > Python' 카테고리의 다른 글
| Python-Matplotlib 패키지 2편 (10) | 2021.06.24 |
|---|---|
| Python-Matplotlib 패키지 1편 (12) | 2021.06.23 |
| Python-배열 4편 (16) | 2021.06.21 |
| Python-배열 3편 (18) | 2021.06.18 |
| Python-배열 2편 (16) | 2021.06.17 |


